4.4 KiB
5、事件驱动数据管理
本书主要介绍如何使用微服务构建应用程序,这是本书的第五章。第一章介绍了微服务架构模式,讨论了使用微服务的优点与缺点。第二和第三章描述了微服务架构内的通信方式对比。第四章探讨了与服务发现相关的内容。在本章中,我们稍微做了点调整,研究微服务架构中出现的分布式数据管理问题。
4.1、微服务和分布式数据管理问题
单体应用程序通常具有一个单一的关系型数据库。使用关系型数据库的一个主要优点是您的应用程序可以使用 ACID 事务,这些事务提供了以下重要保障:
- 原子性(Atomicity) - 所作出的改变都是不可分割的原子操作
- 一致性(Consistency) - 数据库的状态始终保持一致
- 隔离性(Isolation) - 即使事务并发执行,但他们看起来更像是是串行执行
- 永久性(Durable) - 一旦事务提交,它将不可撤销
因此,您的应用程序可以很容易地开始事务、更改(插入、更新和删除)多个行,并提交事务。
使用关系数据库的另一大好处是它提供了 SQL,这是一种丰富的、声明性的和标准化的查询语言。您可以轻松地编写一个查询来组合来自多个表的数据,之后 RDBMS 查询计划程序确定执行查询的最佳方式。您不必担心如何访问数据库等底层细节。因为你所有的应用程序数据都存放在同个数据库中,所以很容易查询。
很不幸的是,当我们转向微服务架构时,数据访问将变得非常复杂。这是因为每个微服务所拥有的数据对当前微服务来说是私有的,只能通过其提供的 API 进行访问。封装数据可确保微服务松散耦合,独立演化。如果多个服务访问相同的数据,模式(schema)更新需要对所有服务进行耗时、协调的更新。
更糟糕的是,不同的微服务经常使用不同类型的数据库。现代应用程序存储和处理着各种数据,而关系型数据库并不总是最佳选择。在某些场景,特定的 NoSQL 数据库可能具有更方便的数据模型,提供了更好的性能和可扩展性。例如,存储和查询文本服务使用文本搜索引擎(如 Elasticsearch)是合理的。类似地,存储社交图数据的服务应该可以使用图数据库,例如 Neo4j。因此,基于微服务的应用程序通常混合使用 SQL 和 NoSQL 数据库,即所谓的混合持久化(polyglot persistence)方法。
一个分区的数据存储混合持久化架构具有许多优点,包括了松散耦合的服务以及更好的性能与可扩展性。然而,它也引入了一些分布式数据管理方面的挑战。
第一个挑战是如何实现维护多个服务之间一致性的业务事务。要了解为什么这是一个问题,让我们先来看一个在线 B2B 商店的示例。Customer Service 维护有关客户的信息,包括信用额度。Order Service 管理订单,并且必须验证新订单不超过客户的信用额度。在此应用程序的单体版本中,Order Service 可以简单地使用 ACID 交易来检查可用信用额度并创建订单。
相比之下,在微服务架构中,ORDER 和 CUSTOMER 表对其各自的服务都是私有的,如图 5-1 所示:
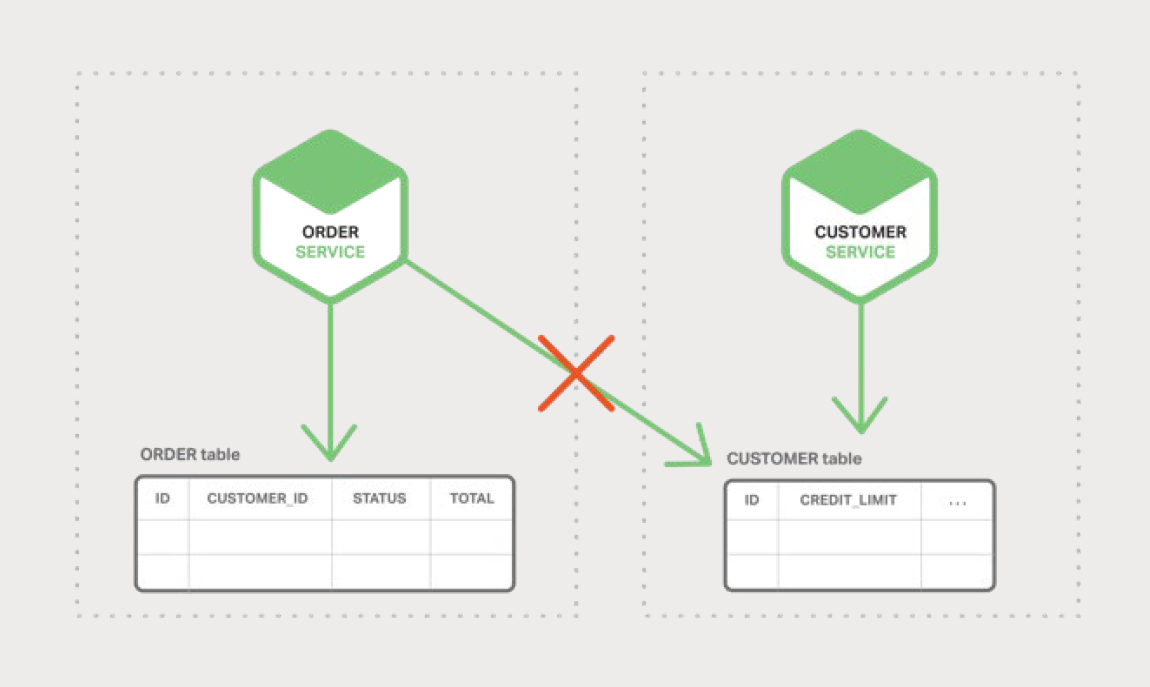
Order Service 无法直接访问 CUSTOMER 表。它只能使用客户服务提供的 API。订单服务可能使用了分布式事务,也称为两阶段提交(2PC)。然而,2PC 在现代应用中通常是不可行的。CAP 定理要求您在可用性与 ACID 式一致性之间作出选择,可用性通常是更好的选择。此外,许多现代技术,如大多数 NoSQL 数据库,都不支持 2PC。维护服务和数据库之间的数据一致性至关重要,因此我们需要另一种解决方案。
第二个挑战是如何实现从多个服务中检索数据。例如,我们假设应用程序需要显示一个客户和他最近的订单。如果订单服务提供了用于检索客户订单的 API,那么您可以使用应用程序端连接以检索数据。应用程序从客户服务中检索客户,并从订单服务中检索客户的订单。但是,假设订单服务仅支持通过主键查找订单(也许它使用了仅支持基于主键检索的 NoSQL 数据库)。在这种情况下,没有有效的方法来检索所需的数据。
待续……